Conditional Generation
Generating images, sound, text, conditioned on latent or observable attributes: sketches, speaker style, music type, instrument.
Pix2Pix
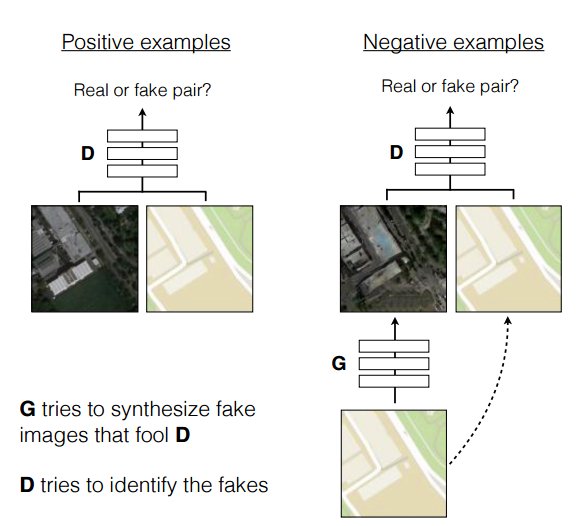
Architecture of a Conditional GAN (image from Isola, Zhu, Zhou, Efros 2016):
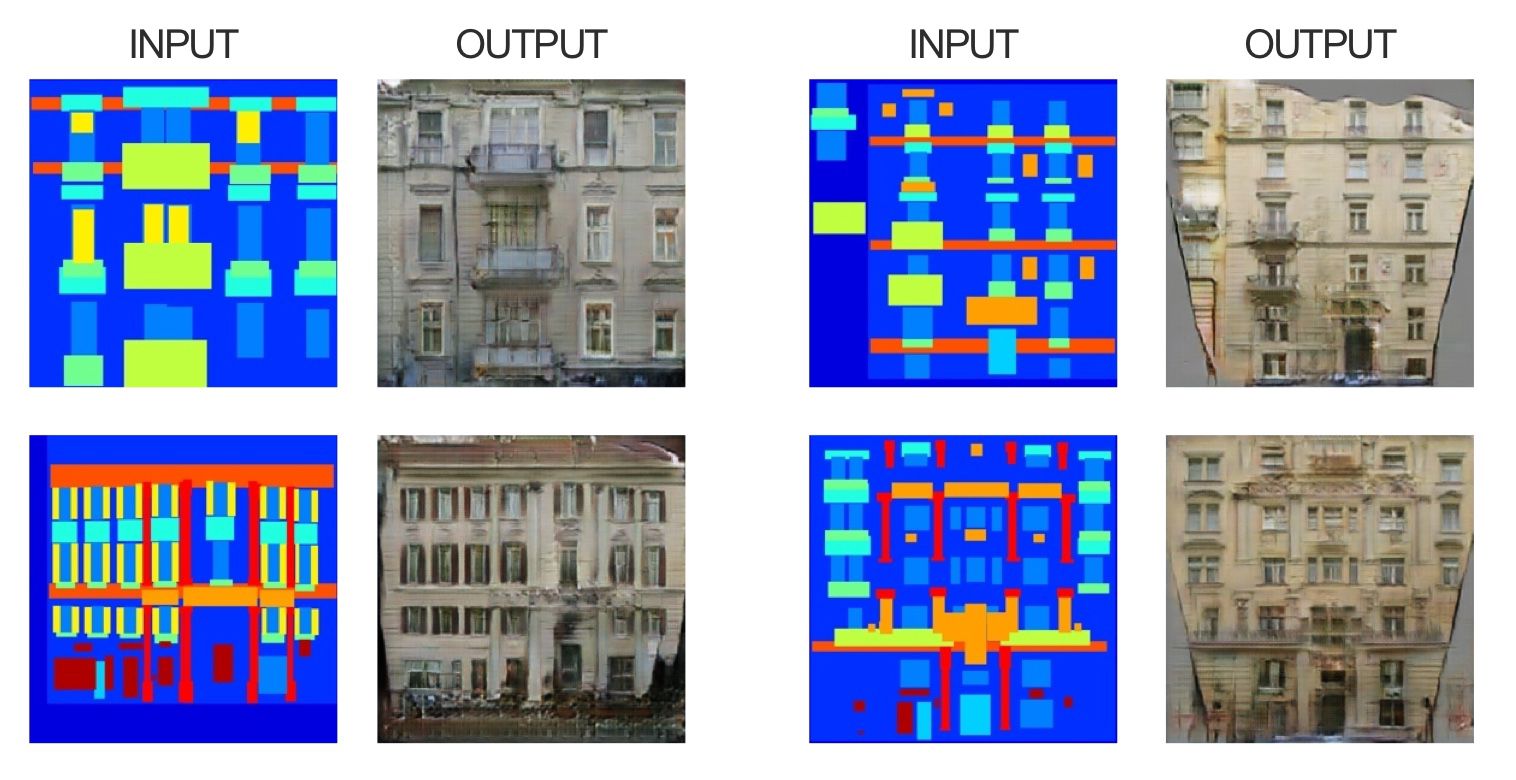
Example of building translation (image from Chistopher Hesse)
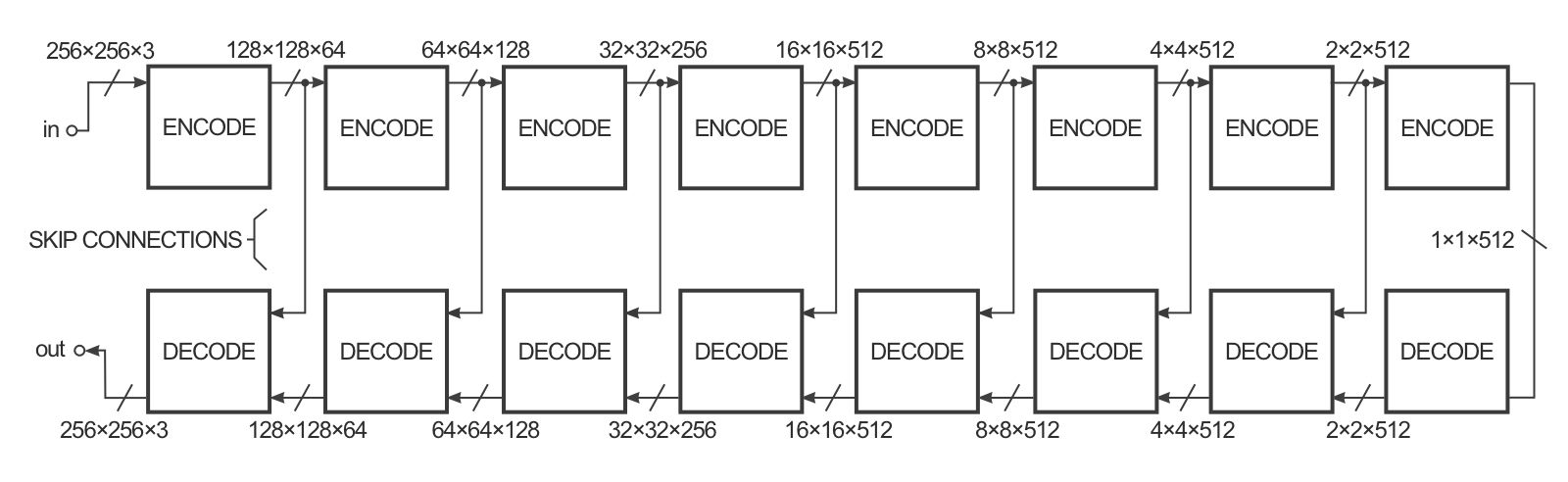
A very good tutorial by Hesse. His illustration of the Pix2Pix architecture.
Keys Ideas:
- Generator is encoder-decoder
- BatchNorm, ReLU
- Skip connections between encoder and decoder
- Discriminator stacks Input/Output on channel axis
Links:
- Isola, Zhu, Zhou, Efros (2016) - Image to Image translation
- Project Page
- Phillip Isola's Torch code
- Christopher Hesse's interactive sketch to Image
Conditional PixelCNN, Gated PixelCNN
Conditional PixelCNNs, also called Gated PixelCNNs, build on Pixel Pixel CNNs, which were introduced in the PixelRNN paper (Oord, Kalchbrenner, Kavukcuoglu (2016) - Pixel RNNs).
Reminder on PixelRNN
![]()
- Row LSTM: condition each row on above row, using 1D convolution -> triangular receptive field
- Diagonal BiLSTM: using a skew trick for parallelization, each pixel depends on a 45-rotated halfspace
- PixelCNN: Like BiLSTM but uses masked convolution to limit receptive field.
The generative process for PixelCNN is as follows:
- For i=1..N, For j=1..M:
- (Sample pixel )
- For l=1..L: # increasing layers
- using masked convolution, convolve upper, left, and upper-left pixel of layer to get activations of layer .
- Now at the last layer , which combines information from all the effective receptive field, compute the distribution . Sample from it to generate pixel .
- Now other pixels to the bottom and right of have their dependencies satisfied, and can be sample as well.
This generative process is very slow when implemented naively because a full forward pass is required just to sample a single pixel. However, training and validating are fully parallel because teacher forcing is used: the ground-truth pixels are used to compute the activations, instead of the generated pixels. Then a single pass allows to train weights for all pixels.
Ideas:
- Use residual connections through LSTMs
- Use masked convolutions for generation (cannot see future) as in Germain, Gregor Murray, Larochelle (2015), MADE which applies it to AE.
- Use softmax over discrete pixel values
Improvements in Gated PixelCNN
Ideas:
- Replace ReLU with gated activation unit
![]()
Applications:
- Image completion
- Image interpolation
![]()
- Class-conditional sampling
![]()
- Text to Image
Links:
- Oord+ (2016), Conditional Image Generation with PixelCNN Decoders
- Kundan's Theano code for PixelCNN
- Tensorflow code for Conditional PixelCNN